Non-English characters
We'll conclude with a very brief glance at text that isn't written in English characters. As linguists, of course, we often want to deal with text that isn't in English, and much of it will be written in some other script.
Sadly, doing this is occasionally a pain. Although modern software offers reasonably good support for non-English scripts, older programs often fail, and there are a variety of (more or less common) legacy systems to deal with.
Before we launch into programming, it's worth understanding a little about how characters are represented on your system. (You can follow along with the Python Unicode HOWTO.)
ASCII: encoding from the dark ages
As you probably know, all the data on your computer is represented as a series of binary digits (bits), 0s and 1s. As with most things on the computer, these numbers have no semantics on their own. They represent more complicated types of data (for instance, the characters of a written text) because the system designers intended them to do so and defined the behavior of the system accordingly.
This means that a text on the computer is internally represented as a series of numbers. The system uses a mapping from numbers to characters to figure out how to turn a given sequence of numbers into a visual representation of the text that you can read.
Until the early 80s, computer users in the USA used a mapping called the American Standard Code for Information Interchange, or ASCII. (This is pronounced 'ass-key'. All the jokes you're now thinking of were made before 1969, so don't bother.)
This is the ASCII chart. The numbers from 0 to 31 are various technical controls for remotely operating a teletype machine (a typewriter controlled via telegraph wire), and the remaining entries (32-127) are the printable characters of standard English text, plus one more special code for DELETE.
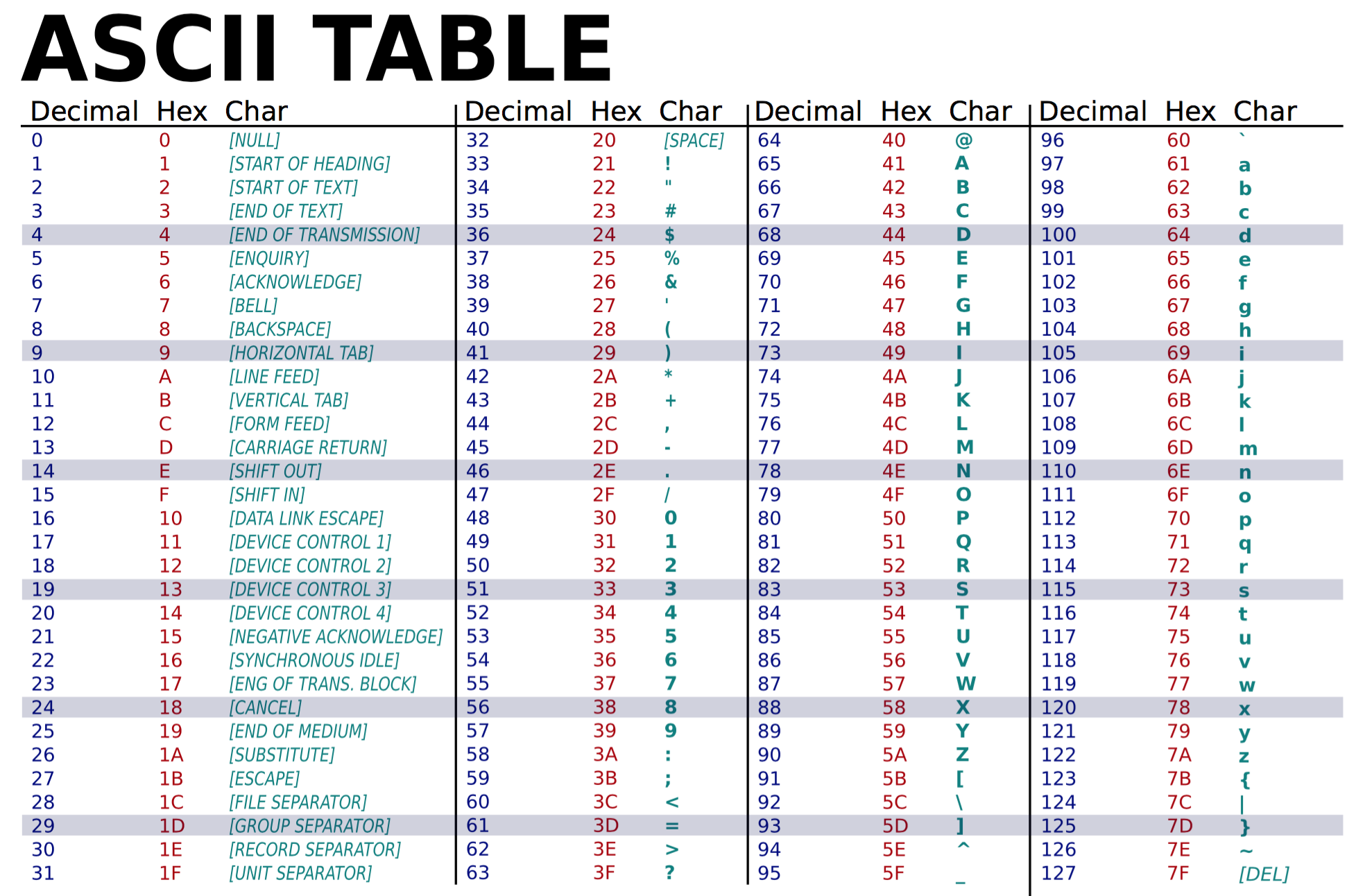 (Wikimedia commons)
(Wikimedia commons)
ASCII has 128 code numbers in all. This is a convenient number for computer people because it is a power of two. (Which power?)
This means that all the numbers from 0 to 127 can be encoded using seven 0s or 1s. For instance, the space, 32, is:
010 0000
What's 97, small 'a'?
This seven-bit system of coding made ASCII compact and easy to interpret, but difficult to extend. Adding, say, the Cyrillic alphabet, would mean having more than 128 characters, and then the characters wouldn't be coded in seven bits anymore.
(In reality, computer systems tended to extend ASCII to 8 bits by tacking on a leading 0. This meant that each character in a sequence would begin at an even position and made things easier to divide up. The extra bit also allowed the system to encode 128 "spare" characters--- but the basic problem still remained. What do you do when you run out of numbers?)
Unicode: shiny new character encoding
The Unicode standard is an attempt to create a character table large enough for anything anyone might conceivably want to write; it contains characters for all the major European, Asian and African scripts, relative rarities like Canadian Aboriginal Syllabics, technical alphabets like the IPA, and even things like Linear B, the Phaistos Disk, and Alchemical Symbols.
Below is a portion of the Unicode chart for Cyrillic. Each character has a number, a glyph (what it looks like onscreen), and a name (what it is). It's the name and number that define a unique Unicode character, not the glyph--- a Cyrillic user writes Cyrillic capital A and an English user writes English A--- even though these are in some sense the same character.
Basic Russian alphabet
0410 А CYRILLIC CAPITAL LETTER A
0411 Б CYRILLIC CAPITAL LETTER BE
→ 0183 ƃ latin small letter b with topbar
0412 В CYRILLIC CAPITAL LETTER VE
0413 Г CYRILLIC CAPITAL LETTER GHE
0414 Д CYRILLIC CAPITAL LETTER DE
0415 Е CYRILLIC CAPITAL LETTER IE
0416 Ж CYRILLIC CAPITAL LETTER ZHE
0417 З CYRILLIC CAPITAL LETTER ZE
0418 И CYRILLIC CAPITAL LETTER I
0419 Й CYRILLIC CAPITAL LETTER SHORT I
≡ 0418 И 0306 $̆
041A К CYRILLIC CAPITAL LETTER KA
041B Л CYRILLIC CAPITAL LETTER EL
041C М CYRILLIC CAPITAL LETTER EM
041D Н CYRILLIC CAPITAL LETTER EN
041E О CYRILLIC CAPITAL LETTER O
041F П CYRILLIC CAPITAL LETTER PE
0420 Р CYRILLIC CAPITAL LETTER ER
0421 С CYRILLIC CAPITAL LETTER ES
0422 Т CYRILLIC CAPITAL LETTER TE
Here are some alchemical symbols:
Symbols for antimony, antimony ore and derivatives 1F72B ALCHEMICAL SYMBOL FOR ANTIMONY ORE = stibnite → 2641 ♁ earth 1F72C ALCHEMICAL SYMBOL FOR SUBLIMATE OF ANTIMONY → 1F739 alchemical symbol for sal-ammoniac 1F72D ALCHEMICAL SYMBOL FOR SALT OF ANTIMONY = cinnabar → 1F714 alchemical symbol for salt 1F72E ALCHEMICAL SYMBOL FOR SUBLIMATE OF SALT OF ANTIMONY 1F72F ALCHEMICAL SYMBOL FOR VINEGAR OF ANTIMONY 1F730 ALCHEMICAL SYMBOL FOR REGULUS OF ANTIMONY = antimony metal 1F731 ALCHEMICAL SYMBOL FOR REGULUS OF ANTIMONY-2
Or, well, here they might be. The text above is copied and pasted from Unicode.org, so it contains the correct numbers. But my computer doesn't have a font which actually displays these characters--- it doesn't have the graphical depictions of the correct glyphs. So instead of translating the numbers into alchemical symbols, it translates them into a series of annoying boxes.
The original document looks like this...
 (Unicode foundation)
(Unicode foundation)
And my editor window looks like this...

We've now covered two of the three things you need to get a Unicode character to display properly:
- The number (or codepoint) of the character has to be correct
- The font you're using has to have a glyph for the character
- The character encoding you're using has to be correct.
So what's a character encoding? In ASCII, we could write each character as a seven (or eight) bit number. Unicode has numbers up to 1114111, which would require 21 bits each. (For the same reason as we rounded up 7 to 8, in practice this would be rounded up to 32.) But this is an awful waste of space... here's the tutorial's example:
P y t h o n 0x50 00 00 00 79 00 00 00 74 00 00 00 68 00 00 00 6f 00 00 00 6e 00 00 00 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
Most of the content is full of 0s! Using this representation would make your web browser or other programs which depend on disk or network access very slow.
Thus, Unicode has several alternate ways of encoding things. The most popular one is called UTF-8 (UTF means "Unicode Transformation Format" and 8 is the number of bits it takes to encode a standard ASCII character). In UTF-8, ASCII characters get 8-bit codes--- in fact, an ASCII character has the same encoding in UTF-8 and in ASCII--- but other characters get longer codes, adding on 8 more bits at a time.
So even if your numbers are correct, if you use the wrong encoding, you'll misinterpret them!
Alternate encodings: annoying, but still popular
Sadly, although Unicode has been around for a while, it has only recently become the standard format for multilingual data. In the era between the dark ages of ASCII-for-everyone and the last ten or fifteen years, many other encodings were created by different language communities.
The most popular of these is ISO-Latin1, an extended ASCII set designed for Western European scripts using a Latin-derived alphabet with some characters that don't appear in English (accents, umlauts, digraphs etc). There's a further extension of this, Windows-1252, which contains all the same stuff and more.
But there are others, including Japanese EUC-JP and Russian KOI8-R.
If you decipher a text which was encoded using one of these systems as if it were UTF-8, the numbers will be misinterpreted (they aren't necessarily 8 bits long, nor are the glyphs that correspond to each number the correct ones). Thus, you will tend to see a series of garbage characters--- some computer scientists use the Japanese term mojibake.
For instance, here's some Japanese text, as rendered by my terminal program:
24-1 <A4><CA> <A4><C0> Ƚ<C4><EA><BB><EC> * Ƚ<C4><EA><BB><EC> <A5><C0><CE><F3> <B4><F0><CB><DC>Ϣ<C2>η<C1> 25-2 <A4>Τ<C7> <A4>Τ<C0> <BD><F5>ư<BB><EC> * <A5>ʷ<C1><CD>ƻ<EC> <A5><C0><CE> <U+E5FF7><CF>Ϣ<CD>ѥƷ<C1> 27-1 <A1><A2> * <C6>ü<EC> <C6><C9><C5><C0> * * * 6 8D + 6 8D <rel type="<A2><E2>" target="ǯƬ" sid="950101008-001" tag="2"/>
And here's some French:
D<E9>bats du S<E9>nat (hansard) 2e Session, 36e L<E9>gislature, Volume 138, Num<E9>ro 53 Le mardi 9 mai 2000 L'honorable Gildas L. Molgat, Pr<E9>sident Table des mati<E8>res D<C9>CLARATIONS DE S<C9>NATEURS
Since most Unix tools default to UTF-8 these days, mojibake is generally a signal that your text is using one of these alternate encodings. Web browsers are somewhat more relaxed and can mostly deal with the ISO-Latin standard as well. Mine displays the French correctly, but for the Japanese text, it merely produces some slightly different-looking mojibake (created by interpreting the Japanese as if it were ISO-Latin1):
# S-ID:950101003-001 KNP:96/10/27 MOD:2005/03/08 * 0 26D + 0 1D 0-2 ¤à¤é¤ä¤Þ * ̾»ì ¿Í̾ * * 2-2 ¤È¤ß¤¤¤Á * ̾»ì ¿Í̾ * * + 1 37D <rel type="=" target="¼»³ÉÙ»Ô" sid="950101003-001" tag="0"/>
Python programming
Now that we understand how these characters are represented, we can start to work with them computationally.
We'll start off with a very simple snippet of Python code, although one which is at the core of all your programs so far.
import sys
for line in open(sys.argv[1]):
print(line.strip())
What does this code do?
Download the multilingual.zip dataset from Carmen. This contains four files from popular corpora--- the Kyoto News Text Corpus, Arabic Gigaword, and the Canadian Hansards (parliamentary records). Run the code on each file in the directory. What happens?
arabic-gigaword1.txt produces correct-looking Arabic text, while the other files cause errors. (This is another difference between Python2 and Python3. In Python2, there is no error, but you do get mojibake.)
By default, Python 3 assumes input files are Unicode, encoded in UTF-8. (Remember, an ASCII file is also a valid UTF-8 file because ASCII characters get the same codes in UTF-8.)
So the three files that don't work are in different encodings. Which ones? Well, there's no completely reliable way to find out. But luckily, we can make some good guesses. The French text is probably in ISO-Latin1... all the non-accented characters (the ones that are the same as ASCII, and thus, as UTF-8) are legible, while the accented ones are broken. We know Latin1 is also the same as ASCII for English characters but provides an alternate encoding for the accented ones.
To try out the Latin1 encoding, modify the encoding argument to open:
for line in open(sys.argv[1], encoding="Latin1"):
You can find the names Python uses for all the encodings here: https://docs.python.org/2/library/codecs.html
Try out your new program. This program should produce correct output for Canadian Hansards:
débats de le Sénat ( hansard ) 1ère Session , 36 e Législature , volume 137 , Numéro 100 le jeudi 3 décembre 1998 le honorable Gildas L . Molgat , Président table de les matières visiteur de marque DÉCLARATIONS DE SÉNATEURS son HonneurM. Pierre Bourque maire de Montréal
What does it produce for the other three files?
Try to figure out what encodings were used for arabic-gigaword2 and kyoto-corpus. Can you make these files display properly?
String literals in your code
There's one final issue between you and correctly processing international corpora. What about when you need to type a string directly into your own code? For instance, we have code like this:
if speakerGender == "m": #m for 'male' utterancesMen += 1 elif speakerGender == "f": #f for female utterancesWomen += 1
Here "m" and "f" are part of the English alphabet. But what if the speaker codes weren't in English?
I've created an annoying alternate-universe version of a Fisher corpus file, alchemical-fisher.txt, which uses the old alchemical/astrological symbols for male and female.
Try editing your code so that it works with this strange version of Fisher. The easiest (and clearest) way to do this is to insert the alchemical symbols directly into your code (instead of "m" and "f"), which you can do by copy-and-pasting them from the data file. Remember to save your code in UTF-8 encoding!
If you couldn't, or didn't want to type the alchemical symbols in directly, you could also refer to them by name using the \N escape sequence. This is particularly useful when you don't have a font that renders the character correctly. In this case, typing it into your code would be very unclear, since you wouldn't be able to tell which character you were looking at:
>>> "\N{male sign}"
'♂'
>>> "\N{female sign}"
'♀'
>>> "\N{ALCHEMICAL SYMBOL FOR SUBLIMATE OF ANTIMONY}"
''